简介¶
torch-sla (Torch Sparse Linear Algebra) 是一个高效的 PyTorch 稀疏线性代数库。它提供可微分的稀疏线性方程求解器,支持多种后端,兼容 CPU 和 CUDA。
核心特性¶
- 内存高效: 仅存储非零元素 — 使用最少内存求解百万级未知数
- 多后端支持: 可选择 SciPy、PyTorch原生、cuDSS(NVIDIA)或 STRUMPACK(支持 CPU/CUDA/ROCm 的可移植直接求解器)
- 后端/方法分离: 独立指定后端和求解方法
- 自动选择: 根据设备、数据类型和问题规模自动选择最佳后端和方法
- 梯度支持: 通过 PyTorch autograd 完整计算梯度,O(1) 计算图节点
- 批量操作: 支持形状为
[..., M, N, ...]的批量稀疏张量 - 属性检测: 自动检测对称性和正定性
- 分布式支持: 支持 halo 交换的分布式稀疏矩阵并行计算
- 大规模测试: 经过 1.69亿自由度 测试,近线性扩展
推荐后端¶
基于 2D Poisson 方程的广泛基准测试(最高测试 1.69亿 DOF):
问题规模 |
CPU |
CUDA (NVIDIA) |
ROCm (AMD) / 备注 |
|---|---|---|---|
小型 (< 10万 DOF) |
|
|
直接求解器,机器精度。ROCm: 用 |
中型 (10万 - 200万 DOF) |
|
|
cuDSS 在 NVIDIA 上最快。ROCm: 用 |
大型 (200万 - 1.69亿 DOF) |
不适用 |
|
仅迭代法,~1e-6 精度。 |
超大型 (> 1.69亿 DOF) |
不适用 |
|
多卡域分解并行(CUDA / ROCm) |
核心发现¶
PyTorch CG+Jacobi 可扩展至 1.69亿+ DOF,近线性 O(n^1.1) 复杂度
直接求解器限于 ~200万 DOF,因内存 O(n^1.5) 填充
迭代法建议用 float64 以获得最佳收敛性
精度权衡: 直接法 = 机器精度 (~1e-14),迭代法 = ~1e-6 但快 100 倍
核心类¶
SparseTensor¶
稀疏矩阵操作的主类。支持批量和块稀疏张量。
from torch_sla import SparseTensor
# 简单 2D 矩阵 [M, N]
A = SparseTensor(values, row, col, (M, N))
# 批量矩阵 [B, M, N]
A = SparseTensor(values_batch, row, col, (B, M, N))
# 求解、范数、特征值
x = A.solve(b)
norm = A.norm('fro')
eigenvalues, eigenvectors = A.eigsh(k=6)
SparseTensorList¶
不同稀疏模式的多个 SparseTensor 的容器。
from torch_sla import SparseTensorList
matrices = SparseTensorList([A1, A2, A3])
x_list = matrices.solve([b1, b2, b3])
DSparseTensor¶
支持域分解和 halo 交换的分布式稀疏张量。
from torch_sla import DSparseTensor
D = DSparseTensor(val, row, col, shape, num_partitions=4)
x_list = D.solve_all(b_list)
LUFactorization¶
LU 分解,用于同一矩阵的高效重复求解。
lu = A.lu()
x = lu.solve(b) # 使用缓存的 LU 分解快速求解
后端¶
后端 |
设备 |
描述 |
推荐 |
|---|---|---|---|
|
CPU |
使用 LU 或 UMFPACK 的 SciPy 后端直接求解器 |
CPU 默认 |
|
CUDA |
NVIDIA cuDSS 直接求解器 (LU, Cholesky, LDLT),仅支持 NVIDIA |
CUDA 直接 |
|
CPU/CUDA/ROCm |
STRUMPACK 多波前稀疏直接求解器 (LU;支持实数与复数;完整 autograd),通过 |
AMD ROCm 直接求解 / 可移植直接法 |
|
CPU/CUDA/ROCm |
PyTorch 原生迭代求解器 (CG, BiCGStab, GMRES, MINRES) + Jacobi 预处理,设备无关 (CPU/CUDA/ROCm) |
大规模问题 (>200万 DOF) |
求解方法¶
直接求解器¶
方法 |
后端 |
描述 |
精度 |
|---|---|---|---|
|
scipy, cudss, strumpack |
LU 分解(一般矩阵,直接法) |
~1e-14 |
|
cudss, strumpack |
Cholesky 分解(对称正定矩阵,最快) |
~1e-14 |
|
cudss, strumpack |
LDLT 分解(对称矩阵) |
~1e-14 |
迭代求解器¶
方法 |
后端 |
描述 |
精度 |
|---|---|---|---|
|
scipy, pytorch |
共轭梯度法(对称正定矩阵)+ Jacobi 预处理 |
~1e-6 |
|
scipy, pytorch |
BiCGStab(一般矩阵)+ Jacobi 预处理 |
~1e-6 |
|
scipy, pytorch |
MINRES(对称不定矩阵)+ Jacobi 预处理 |
~1e-6 |
|
scipy, pytorch |
GMRES(一般矩阵) |
~1e-6 |
快速开始¶
基本用法¶
import torch
from torch_sla import SparseTensor
# 从稠密矩阵创建稀疏矩阵(小矩阵更易读)
dense = torch.tensor([[4.0, -1.0, 0.0],
[-1.0, 4.0, -1.0],
[ 0.0, -1.0, 4.0]], dtype=torch.float64)
# 创建 SparseTensor
A = SparseTensor.from_dense(dense)
# 求解 Ax = b(CPU 上自动选择 scipy+lu)
b = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float64)
x = A.solve(b)
CUDA 用法¶
import torch
from torch_sla import SparseTensor
# 在 CPU 创建,移动到 CUDA
A_cuda = A.cuda()
# 在 CUDA 上求解(小问题自动选择 cudss+cholesky)
b_cuda = b.cuda()
x = A_cuda.solve(b_cuda)
# 对于超大问题 (DOF > 200万),使用迭代法
x = A_cuda.solve(b_cuda, backend='pytorch', method='cg')
配置求解¶
SolverConfig 把一组 solve() 的默认参数
(后端、方法、预条件子、容差)打包,作为上下文管理器或装饰器应用到作用域内的
每一次 solve。调用时显式传入的关键字参数始终优先于作用域:
from torch_sla import solve, SolverConfig
# 上下文管理器:块内每次 solve 都用这些默认值
with SolverConfig(backend="pytorch", method="cg",
preconditioner="amg", atol=1e-8, maxiter=200):
for theta in parameters:
x = solve(A(theta), b) # 采用 cg + amg + atol
x_fast = solve(A(theta), b, atol=1e-4) # 关键字覆盖 atol
# 装饰器形式:把默认值附加到函数
@SolverConfig(backend="cudss", matrix_type="auto")
def gpu_step(A, b):
return solve(A, b) # 默认走 GPU 直接求解
行列式的作用域默认值见 DetConfig。
非线性求解¶
使用伴随法计算梯度求解非线性方程:
from torch_sla import SparseTensor
# 创建刚度矩阵
A = SparseTensor(val, row, col, (n, n))
# 定义非线性残差: A @ u + u² = f
def residual(u, A, f):
return A @ u + u**2 - f
f = torch.randn(n, requires_grad=True)
u0 = torch.zeros(n)
# 使用 Newton-Raphson 求解
u = A.nonlinear_solve(residual, u0, f, method='newton')
# 梯度通过伴随法流动
loss = u.sum()
loss.backward()
print(f.grad) # ∂L/∂f
基准测试结果¶
2D Poisson 方程(5点模板),NVIDIA H200 (140GB),float64:
性能对比¶
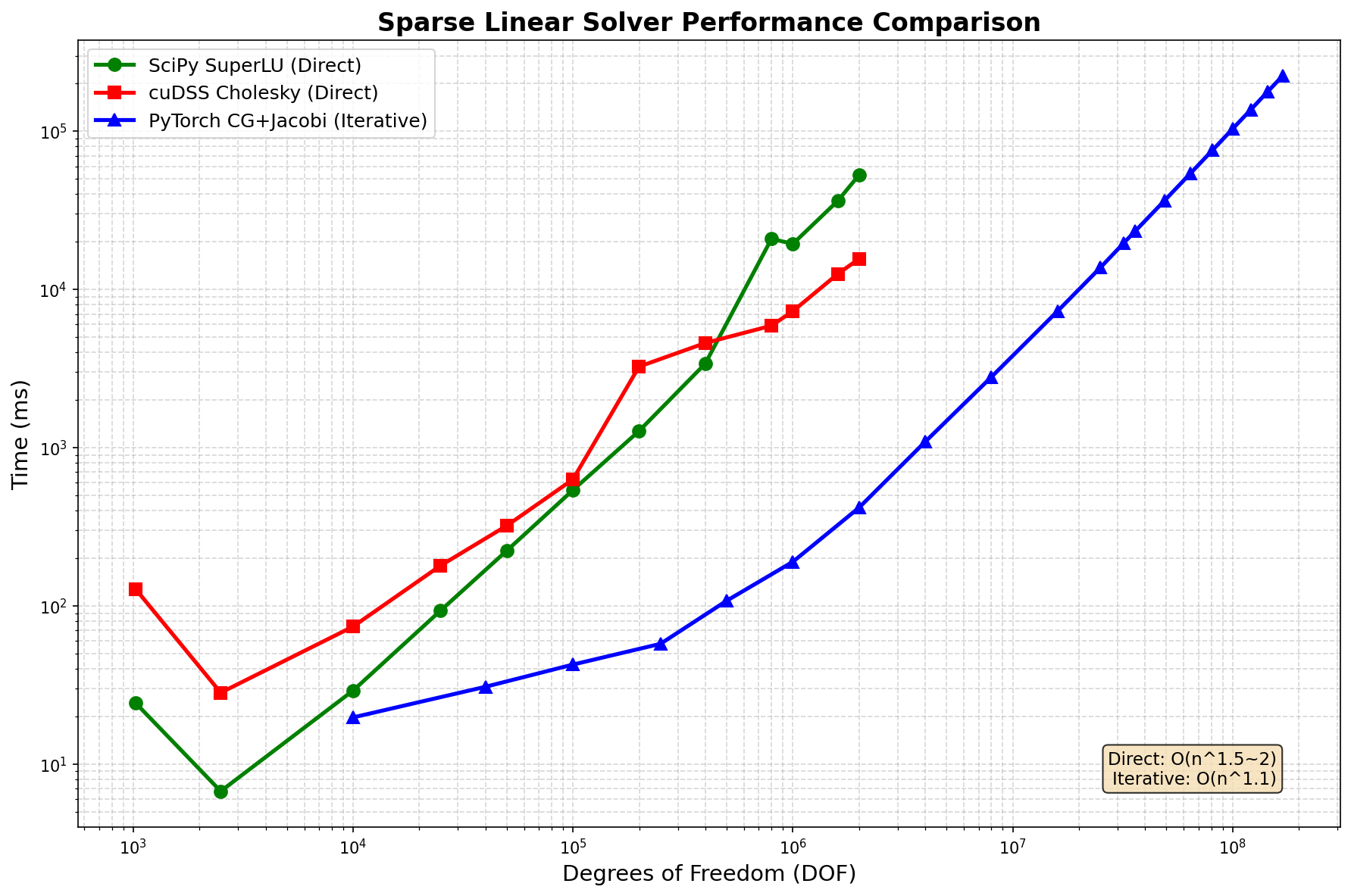
DOF |
SciPy LU |
cuDSS Cholesky |
PyTorch CG+Jacobi |
备注 |
最优 |
|---|---|---|---|---|---|
1万 |
24 |
128 |
20 |
全部很快 |
PyTorch |
10万 |
29 |
630 |
43 |
SciPy |
|
100万 |
19,400 |
7,300 |
190 |
PyTorch 100倍 |
|
200万 |
52,900 |
15,600 |
418 |
PyTorch 100倍 |
|
1600万 |
OOM |
OOM |
7,300 |
仅 PyTorch |
|
8100万 |
OOM |
OOM |
75,900 |
仅 PyTorch |
|
1.69亿 |
OOM |
OOM |
224,000 |
仅 PyTorch |
内存使用¶
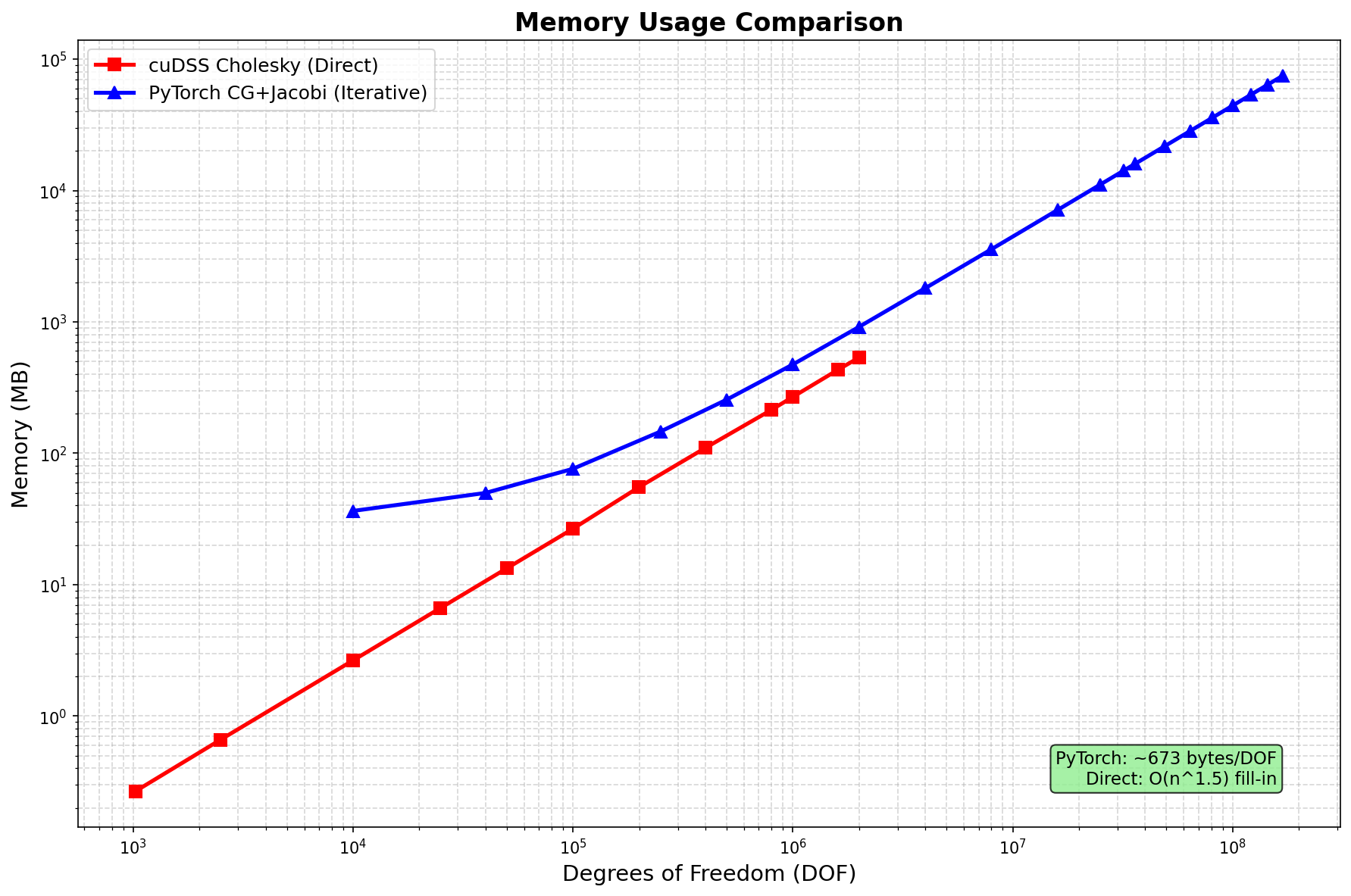
方法 |
内存增长 |
备注 |
|---|---|---|
SciPy LU |
O(n^1.5) 填充 |
仅 CPU,限于 ~200万 DOF |
cuDSS Cholesky |
O(n^1.5) 填充 |
GPU,限于 ~200万 DOF |
PyTorch CG+Jacobi |
O(n) ~443 字节/DOF |
可扩展至 1.69亿+ DOF |
精度对比¶
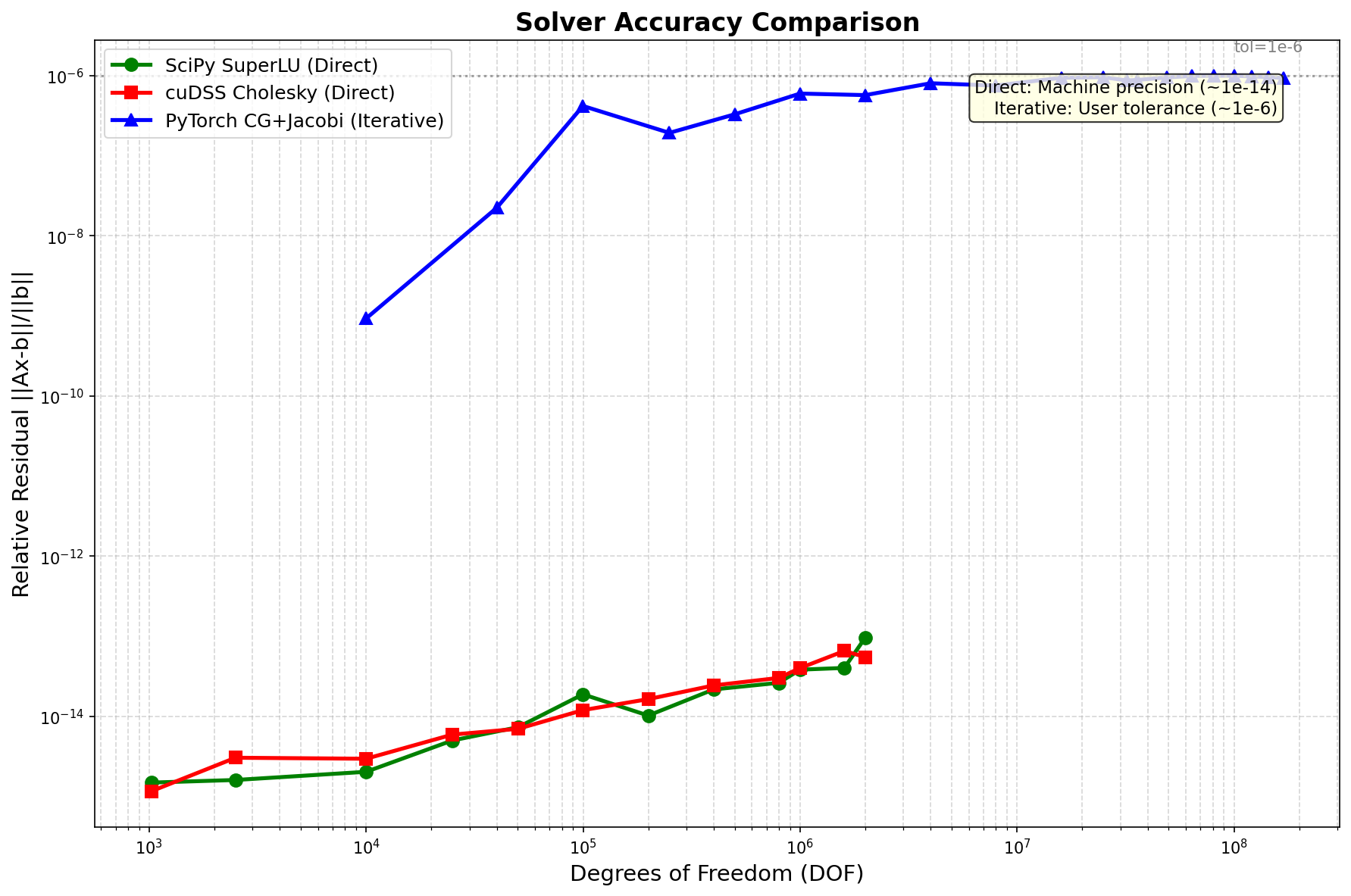
方法类型 |
相对残差 |
备注 |
|---|---|---|
直接法 (scipy, cudss) |
~1e-14 |
机器精度 |
迭代法 (pytorch+cg) |
~1e-6 |
可配置容差 |
核心结论¶
迭代求解器可扩展至 1.69亿 DOF,时间复杂度 O(n^1.1)
直接求解器限于 ~200万 DOF,因 O(n^1.5) 内存填充
PyTorch CG+Jacobi 在 200万 DOF 时比直接法快 100 倍
内存高效: 443 字节/DOF(理论最小值 144 字节/DOF)
精度权衡: 直接法达到机器精度,迭代法达到 ~1e-6
分布式求解(多卡)¶
3-4x NVIDIA H200 GPU + NCCL 后端,可扩展至 4 亿+ DOF:
CUDA (3-4 GPU, NCCL):
DOF |
时间 |
每卡内存 |
GPU 数 |
|---|---|---|---|
1万 |
0.1s |
0.03 GB |
4 |
10万 |
0.3s |
0.05 GB |
4 |
100万 |
0.9s |
0.27 GB |
4 |
1000万 |
3.4s |
2.35 GB |
4 |
5000万 |
15.2s |
11.6 GB |
4 |
1亿 |
36.1s |
23.3 GB |
4 |
2亿 |
119.8s |
53.7 GB |
3 |
3亿 |
217.4s |
80.5 GB |
3 |
4亿 |
330.9s |
110.3 GB |
3 |
核心结论:
可扩展至 4 亿 DOF: 使用 3x H200 GPU(每卡 110 GB)
近线性扩展: 1000 万 → 4 亿 为 40x DOF,~100x 时间
内存高效: ~275 字节/DOF 每 GPU
CUDA 比 CPU 快 12 倍: 10 万 DOF 时 0.3s vs 7.4s
# 使用 3-4 卡运行分布式求解
torchrun --standalone --nproc_per_node=3 examples/distributed/distributed_solve.py
梯度支持¶
所有操作支持 PyTorch autograd 自动微分,使用 O(1) 计算图节点:
SparseTensor 梯度支持
伴随列给出反向传播规则。对标量损失 \(L\),记 \(g = \partial L/\partial x\) 为传入梯度;\(A^{H}\) 为共轭转置。
操作 |
CPU |
CUDA |
伴随 / 梯度 |
备注 |
|---|---|---|---|---|
✓ |
✓ |
\(A^{H}\lambda = g,\ \partial L/\partial A = -\lambda x^{H}\) |
伴随法,O(1) 图节点 |
|
✓ |
✓ |
\(\partial L/\partial A = \sum_i \bar g_{\lambda_i}\, v_i v_i^{H}\)(含特征向量项) |
伴随法,O(1) 图节点 |
|
✓ |
✓ |
\(\partial L/\partial A = \bar g\,\det(A)\,A^{-\top}\)(det);\(A^{-\top}\)(logdet) |
Jacobi 公式,复用 LU 分解 |
|
✓ |
✓ |
\(\partial L/\partial A = U\,\mathrm{diag}(\bar g_\sigma)\,V^{H}\)(含子空间项) |
幂迭代,可微分 |
|
✓ |
✓ |
\(J^{H}\lambda = g,\ \partial L/\partial\theta = -\lambda^{H}\,\partial r/\partial\theta\) |
不动点处伴随,仅参数 |
|
|
✓ |
✓ |
\(\partial L/\partial x = A^{\top}g\) |
标准 autograd |
|
✓ |
✓ |
\(\partial L/\partial A = G\,B^{\top}\)(在稀疏模式上) |
稀疏梯度 |
|
✓ |
✓ |
逐元素;梯度沿模式传递 |
逐元素操作 |
✓ |
✓ |
\(\partial L/\partial A = G^{\top}\) |
类视图,梯度流过 |
|
✓ |
✓ |
标准规约梯度 |
标准 autograd |
|
✓ |
✓ |
将稠密梯度散射回稀疏模式 |
标准 autograd |
DSparseTensor 梯度支持
操作 |
CPU |
CUDA |
备注 |
|---|---|---|---|
|
✓ |
✓ |
分布式矩阵向量乘,伴随 \(A^{\top}g`(``VertexShard`\) halo 交换) |
✓ |
✓ |
分布式 CG / BiCGStab / GMRES,伴随 \(A^{H}\lambda=g\) |
|
✓ |
✓ |
分布式 LOBPCG |
|
✓ |
✓ |
分布式 Newton-Krylov,伴随 \(J^{H}\lambda=g\) |
|
|
✓ |
✓ |
跨 rank |
✓ |
✓ |
Allgather 到全局 |
核心特性:
SparseTensor 对
solve(),eigsh()使用 O(1) 计算图节点 (伴随法)DSparseTensor 使用 真正的分布式算法 (LOBPCG, CG, 幂迭代)
DSparseTensor 核心操作无需数据收集
nonlinear_solve()的梯度流向传递给residual_fn的 参数
后端选择与性能建议见 Performance Tips。
引用¶
如果您在研究中使用了 torch-sla,请引用我们的论文:
论文: arXiv:2601.13994 - Differentiable Sparse Linear Algebra with Adjoint Solvers and Sparse Tensor Parallelism for PyTorch
@article{chi2026torchsla,
title={torch-sla: Differentiable Sparse Linear Algebra with Adjoint Solvers and Sparse Tensor Parallelism for PyTorch},
author={Chi, Mingyuan},
journal={arXiv preprint arXiv:2601.13994},
year={2026},
url={https://arxiv.org/abs/2601.13994}
}